|
ゼミのプログラム演習用サンプルプログラム_機械学習編(このページは該当講座受講登録者向けの情報です)
Pythonによるプログラミング入門
Python実行環境(下記をクリックするとGoogle上でPythonが使えるようになります)
Google Colaboratory Python実行環境
PythonによるAIプログラミング入門 サンプルプログラム集
Google Colaboratoryに下記ソースプログラムを貼り付けて実行して下さい。
#サポートベクタマシンSVMによる文字認識:自分でAIに機械学習をさせる方法
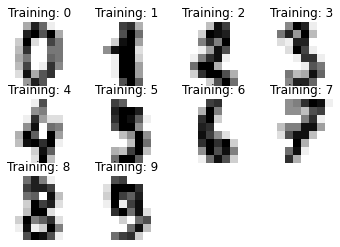
# 例えば 0 の画像は、グレー濃度表記で8×8で下記のデータ形式になっている。
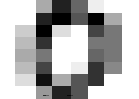 → →
#上記は0という数字であると、AIに機械学習させる
from sklearn.model_selection import train_test_split
from sklearn import datasets,svm,metrics
from sklearn.metrics import accuracy_score
digits = datasets.load_digits()#0-9の画像データを読み込む
print(digits.data)
x = digits.images#画像データ(画像の濃度)
y = digits.target#正解値データ(1とか3とかの)
#二次元配列を一次元配列に変換8bit×8bit(8行×8列)を64個のデータに並べなおす
x = x.reshape((-1,64))
import matplotlib.pyplot as plt
images_and_labels = list(zip(digits.images, digits.target))#画像データと正解値をリスト形式に保存しなおす(繰り返し処理を簡単にするため)
# 画像データセットの最初から10つ[:10]を取り出して評価する
for index, (image, label) in enumerate(images_and_labels[:10]):
plt.subplot(3, 4, index + 1)#画像を複数の領域(3行×4列)に分ける、最後のindex+1は画像を描画する場所(何番目か)を指定している
plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest')
plt.axis('off')
plt.title('Training: %i' % label)
plt.show()
# 元のデータを学習用データと、後で検証するためのテスト用データに分割する
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
# 教師データを元にAIに機械学習を行う
model = svm.LinearSVC()#model:classifier (分類器)
model.fit(x_train, y_train)#教師(トレーニング)データでAIに機械学習を実施
# AIに予測させて、全体で何%正解したのかを表示
y_pred = model.predict(x_test)#テストデータで予測させる
print('0から9までの数字全ての画像を与えた際の、AIの正解率:')
print(accuracy_score(y_test, y_pred))#予測値がどれだけ一致するかを評価する
print('特定の文字列を認識')
y_pred1 = model.predict(digits.data[6:7])#特定の数予測したい場合は[6:7]として[該当の開始番号:該当の終了番号+1]とする。これは6番目(数字は6)を指定している
print('Training6の画像データを与えて、AIが予測した数字:')
print(y_pred1)
#Pythonによる文字認識:tesseract-ocr-jpnという、日本語文字認識の機械学習済のツールを利用する方法
#これは元画像の解像度が低すぎるので、誤認識が多く感じるが、実際のスキャンデータは非常に解像度が高いのでだいぶ誤認識は低くなる
#事前準備
#サンプルの写真 を右ボタンでダウンロードする。 を右ボタンでダウンロードする。
#設定ファイルとサンプル画像のGoogle Colaboratoryへのアップロード
#次のコードを実行し、Google Colaboratory Python実行環境に、上記ファイルをアップロードする。(実行後、「ファイル選択」が表示されるので、それを教えてはファイルを選択し、アップロードをクリックしてアップロードを押す)
from google.colab import files
uploaded = files.upload()
#文字認識のライブラリを使えるようにインストールする(はじめは以下2つの命令で1セットと考えて良い)
!sudo apt-get install tesseract-ocr-jpn
#文字認識のライブラリを使えるようにする
!pip install pytesseract
#-----------ここまでが事前準備 下記が文字認識のプログラム
from PIL import Image#文字認識のライブラリを使えるようにする
import pytesseract#文字認識のライブラリを使えるようにする
myimg = Image.open('toyotaniHP.png')#文字の含まれている画像ファイル名を指定する
text_out = pytesseract.image_to_string(myimg,lang='jpn', config='--psm 6')#文字認識を実行する,psmページセグメンテーションモード(5:縦書 など)
print(text_out)#文字認識の結果を出力する

#上記のプログラムの認識精度を向上させるため、画像の解像度を上げて(OCR向の解像度)認識率を上げたコード
from PIL import Image#文字認識のライブラリを使えるようにする
import pytesseract#文字認識のライブラリを使えるようにする
# 画像を読み込む
myimg = Image.open('toyotaniHP.png')#文字の含まれている画像ファイル名を指定する
# 現在の解像度を300dpiに調整
(width, height) = (int(myimg.width * (300 / 96)), int(myimg.height * (300 / 96)))# 96dpiから300dpiへ
resized_image = myimg.resize((width, height))#解像度をリサイズ・変更する
#print(f'調整後の解像度: {new_width} x {new_height}')# 調整後の解像度を確認
text_out = pytesseract.image_to_string(resized_image,lang='jpn', config='--psm 6')#文字認識を実行する,psmページセグメンテーションモード(5:縦書 など)
print(text_out)#文字認識の結果を出力する

#画像の解像度を上げて(OCR向の解像度)ノイズを除去して認識率を上げたコード
from PIL import Image#文字認識のライブラリを使えるようにする
import pytesseract#文字認識のライブラリを使えるようにする
import numpy as np # #行列計算ライブラリ
import cv2 # Open CVという画像解析ライブラリ
# 画像を読み込む
myimg = Image.open('toyotaniHP.png')#文字の含まれている画像ファイル名を指定する
# 解像度を300dpiに調整
(width, height) = (int(myimg.width * (300 / 96)), int(myimg.height * (300 / 96)))# 96dpiから300dpiへ
resized_image = myimg.resize((width, height))
#print(f'調整後の解像度: {new_width} x {new_height}')# 調整後の解像度を確認
open_cv_image = np.array(resized_image) # PIL ImageをOpenCV形式(NumPy配列)に変換
open_cv_image = open_cv_image[:, :, ::-1].copy() # RGBからBGRに変換 (OpenCVはBGRを使用)
# グレースケール化
gray_myimg = cv2.cvtColor(open_cv_image, cv2.COLOR_BGR2GRAY) # open_cv_imageを使用
# バイラテラルフィルタでノイズ除去
denoised_image = cv2.bilateralFilter(gray_myimg, 9, 75, 75)
#cv2.imwrite('denoised_image.png', denoised_image)# ノイズ除去後の画像を保存
text_out = pytesseract.image_to_string(denoised_image,lang='jpn', config='--psm 6')#文字認識を実行する,psmページセグメンテーションモード(5:縦書 など)
print(text_out)#文字認識の結果を出力する

#PythonによるWebカメラからの顔認識:自分のPCでweb_camera.pyを実行し、Webカメラからリアルタイムに顔を認識するプログラム
#このソースファイル・プログラムコードを右ボタンでダウンロードする。
#顔認識の機械学習済みデータファイルを右ボタンでダウンロードする。
#コマンドプロンプトで、 cd "C:\Users\toyot\Downloads\" と入力し、次に、 python web_camera.py を実行する
#!pip install opencv-python #OpenCVがインストールされていない場合に実行
import cv2# OpenCVライブラリをインポート(画像処理のため)
filepass='haarcascade_frontalface_alt.xml'#機械学習済みのデータファイル
face_cascade = cv2.CascadeClassifier(filepass)#機械学習済みデータファイルの読み込み
web_camera = cv2.VideoCapture(0) # Webカメラチャンネル番号を指定(最初は0で、増設すると1,2,3と増える。標準は最初なので0)
# 撮影=ループ中にフレーム(画像キャプチャー)を1枚ずつ取得(qキーで撮影終了)
while True:# 無限ループでカメラから画像をキャプチャし続ける
ret, frame = web_camera.read() # Webカメラから1フレーム(画像)を取得。retは成功フラグ
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)# 画像をグレースケールに変換(顔認識にはグレースケールが必要)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.3, minNeighbors=5)# 顔認識を実行(スケールファクターと近傍顔数を指定)
for x, y, w, h in faces:# 認識された各顔について、顔領域(x, y, w, h)を取得
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 0, 255), 5)# 顔の周りに赤い(Blue,Green,Red)->(0,0,255) 矩形を描画(顔認識を可視化)
face = frame[y: y + h, x: x + w]# 顔部分を切り抜く(この行は後続の処理で利用する場合がある)
face_gray = gray[y: y + h, x: x + w]# グレースケールの顔部分を切り抜く(後続処理用)
cv2.putText(frame, 'Face Detect!->End to Push [q]', (10,50), cv2.FONT_HERSHEY_SIMPLEX, 1.2, (255,255,255), 2, cv2.LINE_AA)# 画面に「Face Detect!」というメッセージを表示
cv2.imshow('web_camera', frame) # 現在のフレーム(顔認識後の画像)を画面に表示
if cv2.waitKey(1) & 0xFF == ord('q'):# 「q」キーが押された場合、ループを終了
break
# 撮影用オブジェクトとウィンドウの解放
web_camera.release()
cv2.destroyAllWindows()
#Pythonによる顔認識
事前準備 #設定ファイルとサンプル画像のGoogle Colaboratoryへのアップロード
haarcascade_frontalface_alt.xmlと、sample_pict.jpgを別々に2回に分けて次のようにアップします。
サンプルの写真 を右ボタンでダウンロードする。 を右ボタンでダウンロードする。
顔認識の機械学習済みデータファイルを右ボタンでダウンロードする。
次のコードを実行し、Google Colaboratory Python実行環境に、上記ファイルをアップロードする。(2ファイルあるので、2回実施)
from google.colab import files
uploaded = files.upload()
---------------------------------------
#顔認識プログラム
import cv2 #画像処理ライブラリ CV(Computer Vision) が使えるようにする
import matplotlib.pyplot as plt #写真を表示できるようにグラフィックライブラリを読み込む
# 画像読込み
origin_img = cv2.imread("sample_pict.jpg") #自分でアップロードした写真を指定して読み込む
# 基の画像は描画して壊さないように、画像をコピーして利用する
img = origin_img.copy()
# 顔を識別する機械学習済ファイルの読み込み
cascade_path = "haarcascade_frontalface_alt.xml"#顔を識別するAI機械学習済特徴量データを指定
cascade = cv2.CascadeClassifier(cascade_path)# カスケード分類器(学習済みの特徴量データ)を読み込む
grayscale_img = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)# 画像グレースケール化
# 顔検出処理: minSize 最小サイズ指定(100px×100px)
front_face_list = cascade.detectMultiScale(grayscale_img, minSize = (100, 100))# 検出された複数の顔をリスト形式にしてfront_face_listに保存
print("検出判定 [X,Y,幅,高]")# 検出判定
print(front_face_list)#検出された顔の座長X,Y,幅,高をコンソールに出力
if len(front_face_list) == 0:# 検出が無ければ失敗Failedと表示して終了
print("Failed")
quit()
print("検出位置 [X,Y,幅,高]")# 検出位置描画
for (x,y,w,h) in front_face_list:#リストfront_face_listに複数の顔情報があるので、全て一つずつ繰り返し取り出す
print("[x,y] = %d,%d [w,h] = %d,%d" %(x, y, w, h))# 識別できた顔のX,Yや幅と高さを出力
cv2.rectangle(img, (x,y), (x+w, y+h), (0, 0, 255), thickness=10)# 画像の顔部分を四角く囲む
# 顔検出画像表示
plt.imshow(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))# コンピュータのメモリ内に顔を四角く囲った画像を貼り付ける
plt.show()# コンピュータメモリ内の画像を画面に表示する
cv2.imwrite("result_output.jpg", img)# 顔検出画像をファイルに出力する
# 検出画像を個別にファイル(face_x座標-y座長.jpg)として出力
for (x,y,w,h) in front_face_list:#リストfront_face_listに複数の顔情報があるので、全て一つずつ繰り返し取り出す
face_img = origin_img[y:y+h, x:x+w]#顔の部分の画像を、座標と幅、高さを指定して切り取る
filename = "face_" + str(x) + "-" + str(y) + ".jpg"#顔の画像ファイル名をface_x座標-y座長.jpgとする
cv2.imwrite(filename, face_img)#画像をファイルに書き出す
#結果→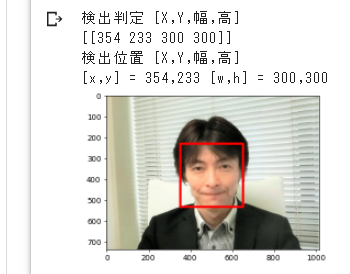
#提出課題 自分で写真を用意(スマホで写メで撮った写真を添付でNu-mail(G-Mail)で添付で送ると、文字列になる)して、それをアップロードして、顔認識をして下さい。
変更箇所:旧>origin_img = cv2.imread("sample_pict.jpg")
変更箇所:新>origin_img = cv2.imread("ここは長い文字列になりますので、Nu-mailから文字列をコピー&ペースト")
出来たら、顔認識課題を開いて[prt Sc]キー(Print Screen)キーを押して(画面イメージをメモリに保存し)、[ctl]+[v](もしくはメニューの編集から貼り付け)で貼り付けて提出して下さい。
上級課題
上記の演習プログラムで切り取られた、個別の顔画像を確認するには次のようにします。
ファイル名の確認は、新たにColaboratory のメニューから [+コード] を選択して、下記 ls (リスト一覧表示)を実行する。
!ls
#結果 face_13-216.jpg face_161-65.jpg ・・・・
個別の顔を表示したい場合は、cv2.imread('face_161-65.jpg') のファイル名を、一致させて実行すれば表示される。
新たにColaboratory のめにゅーから [+コード] を選択して、下記を実行する。
import cv2
im = cv2.imread('face_161-65.jpg')#ここのクォーテーション' の中のファイル名を一致させればよい
from matplotlib import pyplot as plt
plt.axis('off')
im_rgb = cv2.cvtColor(im, cv2.COLOR_BGR2RGB)
plt.imshow(im_rgb)
#結果→  
#Webカメラから自分の顔を撮影して、顔認識をするプログラム
#GoogleColaboratoty の[ランタイム]→[ランタイムのタイムを変更]→[ハードウェアアクセラレータを"T4_GPUなどのGPU"に変更する]
!pip install opencv-python # OpenCVがインストールされていない場合に実行
!pip install face_recognition # 顔認識のface_recognitionライブラリをインストール
from IPython.display import display, Javascript # IPythonのdisplayとJavascriptをインポート(Webカメラを使うために必要)
from google.colab.output import eval_js # Google ColabでJavaScriptを評価するためのeval_jsをインポート
from base64 import b64decode # Base64エンコードされたデータをデコードするためのb64decodeをインポート
import cv2 # 画像処理のOpenCVライブラリをインポート
import face_recognition # 顔認識のface_recognitionライブラリをインポート
from google.colab.patches import cv2_imshow # Google Colabで画像を表示するためのcv2_imshowをインポート
#下記はGoogleColaboratoryのWebカメラからストリームをキャプチャするコードスニペットという機能を利用して作成したものです。(JavaScriptで書かれていてPythonでは無いので、今回はこの関数を単に使うことにします。)
def take_photo(filename='photo.jpg', quality=0.8):
js = Javascript('''async function takePhoto(quality) {
const div = document.createElement('div');
const capture = document.createElement('button');
capture.textContent = 'Capture';
div.appendChild(capture);const video = document.createElement('video');
video.style.display = 'block';
const stream = await navigator.mediaDevices.getUserMedia({video: true});
document.body.appendChild(div);
div.appendChild(video);
video.srcObject = stream;
await video.play();
// Resize the output to fit the video element.
google.colab.output.setIframeHeight(document.documentElement.scrollHeight, true);
// Wait for Capture to be clicked.
await new Promise((resolve) => capture.onclick = resolve);
const canvas = document.createElement('canvas');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
canvas.getContext('2d').drawImage(video, 0, 0);
stream.getVideoTracks()[0].stop();
div.remove();
return canvas.toDataURL('image/jpeg', quality);
}
''')
display(js)
data = eval_js('takePhoto({})'.format(quality))
binary = b64decode(data.split(',')[1])
with open(filename, 'wb') as f:
f.write(binary)
return filename
#Pythonのメイン文
print('画面に自分の顔が写っている事を確認して[Capture]ボタンを押して下さい')
filename = take_photo() # Webカメラから画像をキャプチャし、ファイル名を取得
print('Saved to {}'.format(filename)) # 顔認識をする画像のファイル名を表示
image = face_recognition.load_image_file(filename) # 画像ファイルを読み込む
face_locations = face_recognition.face_locations(image) # 画像内の顔の位置を検出
for (top, right, bottom, left) in face_locations: # 検出した顔の位置に対して処理を行う
cv2.rectangle(image, (left, top), (right, bottom), (0, 255, 0), 2) # 顔の位置に緑色の枠を描画
cv2_imshow(cv2.cvtColor(image, cv2.COLOR_BGR2RGB)) # 画像をRGB形式に変換して表示
#KerasのニューラルネットワークNNを使った機械学習による洋服のカテゴリ分類(TensorFlowのKerasを利用)
from keras.models import Sequential#keras.modelsからニューラルネットワークのSequentialを読み込む
from keras.layers import Activation, Dense, Dropout#NNで利用するツールを読み込む Activation活性化関数、Dense全結合層、Dropout学習時に無効化
from keras.optimizers import RMSprop #NNで利用するオプティマイザ(最適化アルゴリズム)
import numpy as np #行列計算ライブラリ
import matplotlib.pyplot as plt #図形や写真描画をするためのライブラリ
from tensorflow import keras #モジュールのtensorflow.pyの変数kerasをimportする
import pandas as pd
import seaborn as sn
from sklearn.metrics import confusion_matrix
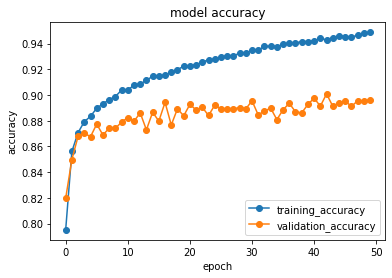
def plot_history(datas):#精度の履歴をプロットする関数plot_historyの定義(引数:historyに学習用データ並びに評価用データに対する精度が保存されている)
plt.plot(datas.history['accuracy'],"o-",label="training_data") #学習用データに対する精度をプロット
plt.plot(datas.history['val_accuracy'],"o-",label="validation_data") #評価用データに対する精度をプロット
plt.title('model accuracy') #タイトル表示
plt.xlabel('epoch') #x軸に繰り返しエポック数epochを表示
plt.ylabel('accuracy') #y軸に精度accuracyを表示
plt.legend(loc="lower right") #凡例の表示を右下に指定する
plt.show() #画面描画(モデルやパラメータ設定等に問題があり、評価用validationデータに対する推定精度の向上がある程度までで止まっている事が分かる)
# 損失の履歴を画面にプロットする
plt.plot(datas.history['loss'],"o-",label="training_data",) #学習用データに対する損失値をプロット
plt.plot(datas.history['val_loss'],"o-",label="validation_data") #評価用データに対する損失値をプロット
plt.title('model loss') #タイトル表示
plt.xlabel('epoch') #x軸に繰り返しエポック数epochを表示
plt.ylabel('loss') #y軸に損失lossを表示
plt.legend(loc='upper right') #凡例の表示を右下に指定する
plt.show() #画面に図を表示する(モデルやパラメータ設定等に問題があり、収束していない事が分かる)
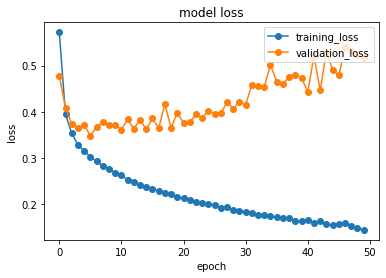
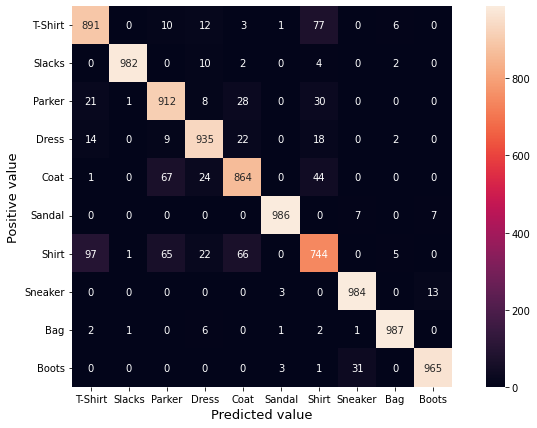
def plot_confusionmatrix(y_true, y_pred): #混同行列の画面表示
class_names = ['T-Shirt', 'Slacks', 'Parker', 'Dress', 'Coat',#洋服の種類名をここで定義する
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boots']
labels = sorted(list(set(y_true))) #項目名を評価用データを昇順に並べる
confusion_matrix_data = confusion_matrix(y_true, y_pred, labels=labels) #評価用データとその予測値を参照して、混同行列データを作成する
df_cmx = pd.DataFrame(confusion_matrix_data, index=class_names, columns=class_names) #混同行列データをデータフレームに入れる
plt.figure(figsize = (12,7)) #混同行列ヒートマップの表示サイズを横1200ピクセル×700ピクセルの大きさで準備する
sn.heatmap(df_cmx, annot=True, fmt='g' ,square = True) #混同行列をヒートマップで作図する
plt.yticks(rotation=0)
plt.xlabel("Predicted value", fontsize=13, rotation=0)
plt.ylabel("Positive value", fontsize=13)
plt.show()#混同行列を画面に表示する
#ここからmain文開始
(train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data()#kerasのdatasetsモジュールからネット経由で洋服のデータセットをダウンロード
#10のクラスにラベル付けされた,50,000枚の32x32訓練用カラー画像,10,000枚のテスト用画像のデータセットを学習用データと評価用データに分けて変数に保存する

#データセットの配布元: GitHub「fashion-mnist/zalandoresearch」。The MIT License (MIT) Copyright クA?[2017] Zalando SE, https://tech.zalando.com 出典: Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. Han Xiao, Kashif Rasul, Roland Vollgraf. arXiv:1708.07747
#入力データをリスト表示
plt.figure(figsize=(10,6))#ファッションデータ描画用に横幅を1000ピクセル(指定の数に100をかけてピクセルに換算)、高さを600ピクセルの画像描画用領域を確保する
plt.xticks([])#x軸のメモリを非表示にする(画像を並べるだけなので、軸の目盛り表記は不要)
plt.yticks([])#x軸のメモリを非表示にする
for i in range(21):#0から1,2,3と、21回繰り返す(横7個×縦3個=21個分)
plt.subplot(3, 7, i+1)#機械学習用(train)教師データの画像を3行×7列の領域に並べて表示する
plt.xticks([])#x軸のメモリを非表示にする(画像を並べるだけなので、軸の目盛り表記は不要)
plt.yticks([])#x軸のメモリを非表示にする
plt.gray()
plt.imshow(train_images[i].reshape(28,28), cmap=None)#教師データ画像を表示する
plt.xlabel("{}".format(class_names[train_labels[i]]),color=("green"))#教師データの名前(ラベル)を表示する
plt.show()
train_images = train_images.reshape((60000, 28 * 28))#2次元縦28×横28=784ピクセルのデータ60000個を、reshapeによって60000個の1次元784ピクセルの1次元データに変換する
train_images = train_images.astype('float32') / 255 #データを(0から255までの)256諧調を255で割って、0.0から1.0に正規化する
test_images = test_images.reshape((10000, 28 * 28))#2次元縦28×横28=784ピクセルのデータ10000個を、reshapeによって10000個の1次元784ピクセルの1次元データに変換する
test_images = test_images.astype('float32') / 255 #データを256諧調から、0.0から1.0に正規化する
# NNのモデルを作成する
model = keras.models.Sequential() #NNのモデルを順番に下記の順で生成する
model.add(Dense(units=512,input_dim=28*28))#ニューラルネットワークを生成:中間層が512個、入力層が28*28=784個のニューロンを生成(追加)
model.add(Activation('relu')) #閾値を計算する活性化関数ReLU(Rectified Linear Unit)ランプ関数で入力が0以下の時は出力も0、入力が0より大きい場合はそのままの値を出力する。
model.add(Dropout(0.2)) #過学習の予防でドロップアウト機能を用いて、全結合の層とのつながりを「20%」無効化する
model.add(Dense(units=10)) #ニューロン10個で構成される中間層を生成(追加)する
model.add(Activation('softmax')) #出力層の活性化関数にsoftmax関数を適用して、最大1で滑らかでソフトな曲線になる。
model.compile(loss='sparse_categorical_crossentropy',optimizer=RMSprop(),metrics=['accuracy'])#トレーニング(機械学習)に時間が掛かるので、その時のアルゴリズムを最適化する。
# ラベルが整数なので、損失関数としてsparse_categorical_crossentropy を用いる。RMSpropはAdaGradを改良したアルゴリズムで勾配の2乗の指数移動平均を取る
# NNによる機械学習を実行
history = model.fit(train_images, train_labels, #機械学習用データを入力データtrain_images,出力データが train_labelsとして記憶させる
batch_size=32,#64,128など変えて実施してみましょう
epochs=3,#50くらいやると良いが、演習では時間が無く小さくしている
verbose=1, #障害解析などに必要な詳細情報を出力するためのログ出力レベル
validation_data=(test_images, test_labels))#評価用データとして入力データtest_images,出力データが test_labelsとして指定する(まだ評価は実行はしない)
# 機械学習に対する精度の履歴データをhistoryに保存する
plot_history(history) #機械学習をした時の精度の履歴データhistoryを画面に表示する
score = model.evaluate(test_images, test_labels, verbose=1)#評価用データとして入力データtest_images,出力データが test_labelsとして実行して評価する。その結果をscoreに代入する。verboseは1:計算途中のログ表示有、0:ログ無し
print('loss=', score[0])#画面に損失関数lossを表示する
print('accuracy=', score[1])#画面に精度accuracyを表示する
predict_y=model.predict(test_images) #評価用データtest_imagesを使って、その商品の商品カテゴリpredict_yを推測させる
predict_classes=np.argmax(predict_y,axis=1)
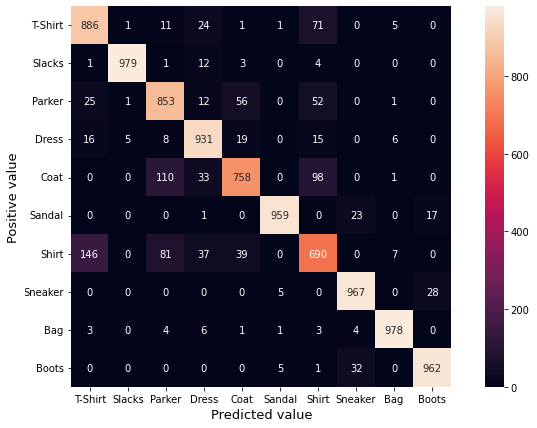
plot_confusionmatrix(test_labels, predict_classes)#正解と推測の混同行列を表示する
class_names = ['T-Shirt', 'Slacks', 'Parker', 'Dress', 'Coat',#洋服の種類名をここで定義する
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boots']
predict_labels = model.predict(test_images)#機械学習に基づく予測を計算する
true_labels = test_labels#答えを設定する
figure = plt.figure(figsize=(10, 6))#ファッションデータ描画用に横幅を1000ピクセル(指定の数に100をかけてピクセルに換算)、高さを600ピクセルの画像描画用領域を確保する
for index in range(21):#0から1,2,3と、15回繰り返す(横5個×縦3個=15個分)
plt.subplot(3,7,index+1)#train教師データの画像を3行×7列の領域に並べて表示する
plt.xticks([])#x軸のメモリを非表示にする(画像を並べるだけなので、軸の目盛り表記は不要)
plt.yticks([])#x軸のメモリを非表示にする
predict_index = np.argmax(predict_labels[index]) #予測した分類番号を取得する
true_index =true_labels[index] #正解の分類番号を取得する
plt.imshow(test_images[index].reshape(28,28), cmap=None)#教師データ画像を表示する
plt.xlabel("{} ({})".format(class_names[predict_index],#画面に予測した分類名を表示する
class_names[true_index]),#カッコ内( )に正解の分類名を表示する
color=("blue" if predict_index == true_index else "red"))#予測が当たっていたら青色で、間違っていたら赤色で表示する。正解はカッコ内

#計算結果
#loss= 0.5688106417655945
#accuracy= 0.8858000040054321
---------------------------------------
#CNNによる洋服のカテゴリ分類(TensorFlowのKerasを利用)
import numpy as np #行列計算ライブラリ
import matplotlib.pyplot as plt #図形や写真描画をするためのライブラリ
import tensorflow as tf #深層学習でGPUを簡単に使うことができる行列計算ライブラリ
from tensorflow import keras #よりニューラルネットワークの実装の際に便利な機能がまとめられたライブラリ
import pandas as pd #データ解析ライブラリ。今回は混合行列作成の際にデータフレームを利用するために読み込む
import seaborn as sn #グラフや図を見栄え良くするライブラリ
from sklearn.metrics import confusion_matrix #混合行列を作成するためのライブラリ
def plot_history(datas):#精度の履歴をプロットする関数plot_historyの定義(引数:historyに学習用データ並びに評価用データに対する精度が保存されている)
plt.plot(datas.history['accuracy'],"o-",label="training_data") #学習用データに対する精度をプロット
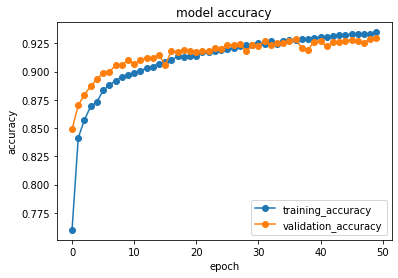
plt.plot(datas.history['val_accuracy'],"o-",label="validation_data") #評価用データに対する精度をプロット
plt.title('model accuracy') #タイトル表示
plt.xlabel('epoch') #x軸にエポック数epochを表示
plt.ylabel('accuracy') #y軸に精度accuracyを表示
plt.legend(loc="lower right") #凡例の表示を右下に指定する
plt.show() #画面描画(下の図は精度が頭打ちになって収束している事が分かる。training_data(教師データ)とvalidation_data(評価データ)があり、まずtraining_data(教師データ)を使って機械学習をした後に精度を評価する。その際にtraining_accuracy(教師データに対する精度)とvalidation_accuracy(評価データに対する精度)の両方を算出するが、学習後に精度を評価するvalidation_accuracy(評価データに対する精度)の方が精度は良くなる特性がある。ただしvalidation_data(評価データ)は未知のデータなので、精度向上には限界がある。しかし、training_data(教師データ)を使った評価は、既に機械学習で覚えたデータを使うので、epochが進んで学習を繰り返せば1.0(100%)に近づく。そのために初めはvalidationが高いが、epochの増加と共にtrainingの方が精度は向上する。ただし重要なのはvalidationの精度である。学習の繰り返しをepochと言い、epochの増加(学習の繰り返し)と共にvalidation_accuracy(評価データに対する精度)が悪化して下がってくる事があり、それは過学習をしている状況である。)
# 損失の履歴をプロット
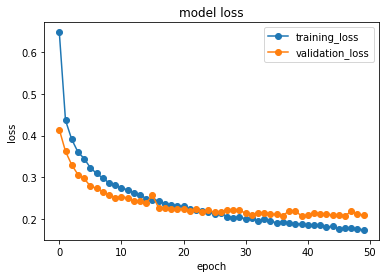
plt.plot(datas.history['loss'],"o-",label="training_data",) #学習用データに対する損失値をプロット
plt.plot(datas.history['val_loss'],"o-",label="validation_data") #評価用データに対する損失値をプロット
plt.title('model loss') #タイトル表示
plt.xlabel('epoch') #x軸にエポック数epochを表示
plt.ylabel('loss') #y軸に損失lossを表示
plt.legend(loc='upper right') #凡例の表示を右下に指定する
plt.show() #画面に図を表示する(収束している事が分かる。epochの増加(学習の繰り返し)と共にloss(損失:正解値と推測値の差)が増えれば過学習をしている。)
def plot_confusionmatrix(y_true, y_pred): #混同行列の画面表示
class_names = ['T-Shirt', 'Slacks', 'Parker', 'Dress', 'Coat',#洋服の種類名をここで定義する
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boots']
labels = sorted(list(set(y_true))) #項目名を評価用データを昇順に並べる
confusion_matrix_data = confusion_matrix(y_true, y_pred, labels=labels) #評価用データとその予測値を参照して、混同行列データを作成する
df_cmx = pd.DataFrame(confusion_matrix_data, index=class_names, columns=class_names) #混同行列データをデータフレームに入れる
plt.figure(figsize = (12,7)) #混同行列ヒートマップの表示サイズを横1200ピクセル×700ピクセルの大きさで準備する
sn.heatmap(df_cmx, annot=True, fmt='g' ,square = True) #混同行列をヒートマップで作図する。
plt.yticks(rotation=0)
plt.xlabel("Predicted value", fontsize=13, rotation=0)
plt.ylabel("Positive value", fontsize=13)
plt.show()#混同行列を画面に表示する 横軸が推測した種類(Predicted value)、縦軸が正解の種類(Positive value)なので、推測した分類が正解したら対角線にカウントされる。
#ここからmain文開始
(train_images, train_labels), (test_images, test_labels) = keras.datasets.fashion_mnist.load_data()#kerasのdatasetsモジュールからネット経由で洋服のデータセットをダウンロード
#データセットの配布元: GitHub「fashion-mnist/zalandoresearch」。The MIT License (MIT) Copyright クA?[2017] Zalando SE, https://tech.zalando.com 出典: Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms. Han Xiao, Kashif Rasul, Roland Vollgraf. arXiv:1708.07747
class_names = ['T-Shirt', 'Slacks', 'Parker', 'Dress', 'Coat',#洋服の種類名をここで定義する
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Boots']
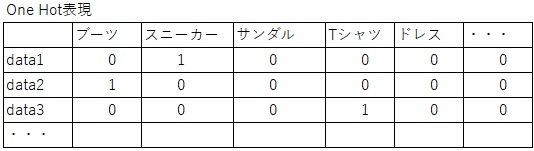
train_labels_onehot = keras.utils.to_categorical(train_labels, 10)#one hot表現とは該当列のみ1を立てて、他は0で埋める形式のデータである。
test_labels_onehot = keras.utils.to_categorical(test_labels, 10)
train_images = train_images.astype("float32") / 255.0 #train教師データの画素値を0.0から1.0に正規化をする(最大値が255のため255で割る)
test_images = test_images.astype("float32") / 255.0 #testテストデータの画素値を0.0から1.0に正規化をする(最大値が255のため255で割る)
#入力データをリスト表示
plt.figure(figsize=(10,6))#ファッションデータ描画用に横幅を1000ピクセル(指定の数に100をかけてピクセルに換算)、高さを600ピクセルの画像描画用領域を確保する
for i in range(15):#0から1,2,3と、15回繰り返す(横5個×縦5個=15個分)
plt.subplot(3,5,i+1)#train教師データの画像を3行×5列の領域に並べて表示する
plt.xticks([])#x軸のメモリを非表示にする(画像を並べるだけなので、軸の目盛り表記は不要)
plt.yticks([])#x軸のメモリを非表示にする
plt.imshow(train_images[i], cmap=plt.cm.binary)#教師データ画像を表示する
plt.xlabel("{}".format(class_names[train_labels[i]]),color=("green"))#教師データの名前(ラベル)を表示する
plt.show()#混同行列を画面に表示する

# CNNのモデルを作成する
model = keras.Sequential([ #モデルの構築:この書式は非常に長く、順に記載するが、順番に Conv2D, MaxPooling2D, Dropout, ・・・指定した順に中間層を追加する
keras.layers.Conv2D(filters=64, kernel_size=(2,2), padding="same", activation="relu", input_shape=(28,28,1)),#フィルター数はカーネルや特徴量検出器の数
# filters=64 64枚のフィルター(特徴量検出器)を使う
# kernel_size=(2,2) 図では赤枠の3×3であるが、ここでは2×2の画像を探索対象にする
# padding="same"特徴マップの周囲を0で埋めて(ゼロパディング)出力も同じサイズにする。padding="valid"とすると特徴マップの周囲に0は入れないため、出力の特徴マップデータは小さくなる。
# activation="relu"ReLU(Rectified Linear Unit)- ランプ関数: 0より大きい数はそのままで、0以下は0に置き換える関数を採用する
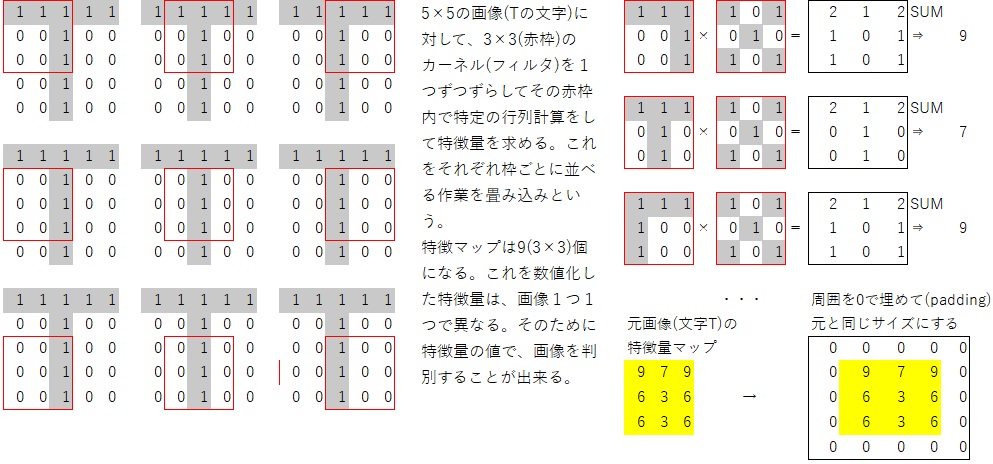
keras.layers.MaxPooling2D(pool_size=(2,2)),#2×2の画像を探索して、最大値で置き換えて画像サイズを小さくする(プーリング)。通常はデータのサイズが大きいために、この畳み込み処理やプーリングを繰り返してサイズを小さくする。

keras.layers.Dropout(0.3),#過学習を回避するためにドロップアウト層を追加する。ニューラルネットワークの中間層のニューロンをランダムに非活性化させることによって、機械学習を難しくさせて、汎化性能を向上させる役割がある。(値は任意だが一般には0.25から0.3くらい)
keras.layers.Conv2D(filters=32, kernel_size=(2,2), padding="same", activation="relu"),#畳込み層(レイヤー):上記を繰り返す事で、大きな画像を小さくすることが出来る。また特徴量の畳み込み計算を行う
keras.layers.MaxPooling2D(pool_size=(2,2)),#図は赤枠3×3であるが、ここでは2×2の領域(カーネル)内で最大値のみを取り出して、レイヤーを縮小してデータ量を減らす
keras.layers.Dropout(0.3),#過学習を回避するためにドロップアウト層を追加する(値は任意だが一般には0.25から0.3くらい)
keras.layers.Flatten(),#8x8の二次元配列を64要素の一次元配列に直すして、次にニューラルネットワークの入力層にする。
keras.layers.Dense(256, activation="relu"),#ニューラルネットワークの中間層をユニット数256として作成する。閾値を計算する活性化関数ReLU(Rectified Linear Unit)ランプ関数で入力が0以下の時は出力も0、入力が0より大きい場合はそのままの値を出力する。
keras.layers.Dropout(0.5),#過学習を回避するためにドロップアウト層を追加する。
keras.layers.Dense(10, activation="softmax")#ニューラルネットワークの中間層をさらにユニット数10で作成する。活性化関数は各データを正規化しての出力値の合計が1.0(=100%)になるように変換して出力する関数。各出力値の範囲は0.0~1.0となる。softmax関数を使うため、最大1で滑らかでソフトな曲線になる。
])
#この設定で左側に画像データを畳み込み処理をした特徴量が入力層になり、右側の出力層に洋服の分類番号がセットされる。この後の機械学習でその入力を行うとその出力値になるように、ニューラルネットワークの重みが自動計算される。
model.compile(optimizer=tf.optimizers.Adam(),#トレーニング(機械学習)に時間が掛かるので、その時のアルゴリズムを最適化する
loss='categorical_crossentropy',#複数の画像があり、それぞれTシャツやスニーカーなど、1つのラベルに分類する問題ではcategorical_crossentropyを指定する。2値分類の時はbinary_crossentropyを指定する
metrics=["accuracy"])#評価関数であり、学習の評価として正解率も計算するように指定している
history = model.fit(train_images[:,:,:,None], train_labels_onehot, #機械学習用データを入力データx_train,出力データが y_trainとして記憶させる
batch_size=32,#64,128など変えてみて下さい
epochs=3,#50くらいやると良いが、演習では時間が無く小さくしている
verbose=1, #障害解析などに必要な詳細情報を出力するためのログ出力レベル
validation_data=(test_images[:,:,:,None], test_labels_onehot))#評価用データとして入力データx_test,出力データが y_testとして指定する(まだ評価は実行はしない)
# 機械学習に対する精度の履歴データをhistoryに保存する
plot_history(history) #機械学習をした時の精度の履歴データhistoryを画面に表示する
labels = model.predict(test_images[:,:,:,None])#機械学習に基づく予測を計算する
score_loss, score_metrics = model.evaluate(test_images[:,:,:,None], test_labels_onehot)#機械学習の予測結果が一致しているかを評価する
print('機械学習後の損失関数値: ', score_loss)
print('機械学習後の評価関数値: ', score_metrics)
predict_classes=np.argmax(labels,axis=1)#推測データが全クラスに対して0.0から1.0までの実数値になっているため、1.0(最大値)に近いのは何番目かを求める。これが推測したクラス番号になる
plot_confusionmatrix(test_labels, predict_classes)#正解と推測の混同行列を表示する
figure = plt.figure(figsize=(10, 6))#データ描画用に横幅を1000ピクセル(指定の数に100をかけてピクセルに換算)、高さを600ピクセルの画像描画用領域を確保する
for index in range(15):#0から1,2,3と、15回繰り返す(横5個×縦3個=15個分)
plt.subplot(3,5,index+1)#train教師データの画像を3行×5列の領域に並べて表示する
plt.xticks([])#x軸のメモリを非表示にする(画像を並べるだけなので、軸の目盛り表記は不要)
plt.yticks([])#x軸のメモリを非表示にする
predict_index = np.argmax(labels[index]) #予測した分類番号を取得する
true_index = np.argmax(test_labels_onehot[index]) #正解の分類番号を取得する
plt.imshow(test_images[index], cmap=plt.cm.binary)#教師データ画像を表示する
plt.xlabel("{} ({})".format(class_names[predict_index],#画面に予測した分類名を表示する
class_names[true_index]),#カッコ内( )に正解の分類名を表示する
color=("blue" if predict_index == true_index else "red"))#予測が当たっていたら青色で、間違っていたら赤色で表示する
#参考(教師データ)
#結果(青は正解、赤は不正解)

#計算結果
#機械学習による予測結果の評価: [0.21398799121379852, 0.9258000254631042]
#機械学習後の損失関数値: 0.21398799121379852
#機械学習後の評価関数値: 0.9258000254631042
---------------------------------------
#OpenCVのスーパーピクセル(領域分割)を利用した画像のセグメンテーション
import cv2 #画像処理ライブラリ CV(Computer Vision) が使えるようにする
import math#乱数や数学関数を利用するためのライブラリ
import numpy as np #行列計算ライブラリ
from google.colab.patches import cv2_imshow
import urllib.request as req # URL指定でファイルをダウンロードするのに利用
url_img = 'https://www.toyotani.org/lib/lib/toyotani2017s.jpg' # サンプル画像を取得する
req.urlretrieve(url_img, "target.jpg") # 入力画像としてGoogleColaboratoryに保存(既にファイルがあればこの処理不要)
input_image_data = cv2.imread('target.jpg')
if input_image_data is None:
print("ファイルオープンエラー")
# 色やテクスチャが類似するピクセルをグループ化した領域superpixel(スーパーピクセル)の生成処理の開始
height, width, channels= input_image_data.shape[:3]#shape[:3]を0から2(3-1)まで回し、
input_image_data = cv2.resize(input_image_data,(int (width/2), int (height/2) ))
cv2_imshow(input_image_data)#元の画像表示
height, width, channels= input_image_data.shape[:3]#shape[:3]を0から2(3-1)まで回して取得する
# 元の画像データ配列の0番が高さ、1番が幅、2番がチャネル数なのでそれらを取得する
num_iterations = 4 #ピクセル毎のグループ化の反復回数で、数値が大きいほど精度が向上する。
prior = 5 #領域分割の平滑オプション(0~5)で値が大きいほど滑らかになる
double_step = False #Trueの場合、精度を高めるために各ブロックレベルをダブルで行なう。
num_superpixels =15 #生成するスーパーピクセルセグメンテーション数(実際はこれより小さくなる事が多い)
num_levels = 5 #領域分割のブロックレベルの数。この値が高いほどセグメンテーションの精度は高くなる。
num_histogram_bins = 4 #ヒストグラムビンの数(ヒストグラムの棒の数)
seeds = cv2.ximgproc.createSuperpixelSEEDS(width, height, channels, num_superpixels,
num_levels, prior, num_histogram_bins, double_step)#スーパーピクセルの生成
# OpenCVで入力画像はBGR形式であるため、HSV形式「色相(Hue)、彩度(Saturation)、明度(Value・Brightness)」の3要素に変換する
converted = cv2.cvtColor(input_image_data, cv2.COLOR_BGR2HSV) # BGR形式からHSV形式へ変換
seeds.iterate(converted, num_iterations)# スーパーピクセルセグメンテーションを実行
contour_mask = seeds.getLabelContourMask(False) # スーパーピクセルセグメンテーションの境界を取得
result = input_image_data.copy()# 元の画像を保持してresultという変数にコピーする
result[0 < contour_mask] = ( 0, 255, 255)#ピクセルが境界領域であれば黄色を指定
num_segment = seeds.getNumberOfSuperpixels() # セグメンテーション数の取得
labels = seeds.getLabels() # セグメンテーション分割情報の取得
# セグメンテーション毎にランダムに色付を行う
randcolor = np.random.randint(255, size=[num_segment,3]) # 0-255までに、256色にランダムに色を決定
rand_img = np.zeros((height, width, channels), dtype=np.uint8) # 画像の変数を初期化
for m in range(0, num_segment): # 分割されたセグメントの数だけ繰り返す
rand_img[labels == m] = randcolor[m] # 分割された各セグメントに色番号を指定する
cv2_imshow(rand_img)#各領域にランダムに色を割り当てが結果を表示する
# セグメンテーション毎のBGR平均値seg_avg_imgを取得
seg_avg_img = np.zeros((height, width, channels), dtype=np.uint8) # 画像の変数を初期化
mask = np.zeros((height, width), dtype=np.uint8) # 画像の変数を初期化
for m in range(0, num_segment): # 分割されたセグメントの数だけ繰り返す
mask.fill(0) # マスク画像用の変数を黒く初期化する
mask[labels == m] = 255 # セグメント分割されていれば、255 で白色にしてマスク部分を指定する
img_mask_mean = cv2.mean(input_image_data, mask) # 画像とマスク画像を指定して、BGR平均値を取得
# tuple float形式の平均値情報をint形式に変換
bgr_color = [int(img_mask_mean[0]), int(img_mask_mean[1]), int(img_mask_mean[2])]
seg_avg_img[mask == 255] = bgr_color#境界だったら
cv2_imshow(result) # 元の画像に境界部分を黄色くした画像を表示する
cv2_imshow(seg_avg_img)

---------------------------------------
#Instance Segmentation: Facebookの人工知能研究グループにより初期開発されたPyTorchのdetectron2を利用した物体認識処理プログラム。GoogleColaboratory は標準でPyTorchが組み込まれているので、!pip install torchvision等は不要
#GoogleColaboratoty の[ランタイム]→[ランタイムのタイムを変更]→[ハードウェアアクセラレータを"GPU"にする]
!python -m pip install pyyaml==5.1 # YAMLデータファイルを使用するのでPyYAMLというライブラリが必要
import sys, os, distutils.core #後でDistutilsを使うためにdistutils.coreを読み込む必要がある
!git clone 'https://github.com/facebookresearch/detectron2' #detectron2というInstance Segmentationの機能を、ネットから自分の作業場所にclone(コピー)する
dist = distutils.core.run_setup("./detectron2/setup.py") # detectron2を利用するために必要なセットアップを行う
!python -m pip install {' '.join([f"'{x}'" for x in dist.install_requires])}
sys.path.insert(0, os.path.abspath('./detectron2')) #detectron2の中に置いたパッケージ・ライブラリがいつでも使えるようになる
#ここから下がプログラムで、上記は下記を動かすための設定
import torch, detectron2 #Detectron2は Facebook AIが開発した、インスタンスセグメンテーション用PyTorchベースの物体検出のライブラリ
!nvcc --version
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1] # cuda versionのチェック
#print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
#print("detectron2:", detectron2.__version__)
# Detectron2 loggerの設定
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# 共通ライブラリの読み込み
import numpy as np #行列計算ライブラリ
import os, json, cv2, random # osファイルやディレクトリの操作などの読み込み
from google.colab.patches import cv2_imshow # GoogleColaboratoryでcv_imshowを実行するのに利用
# detectron2 utilitiesの共通部品を読み込む
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
!wget https://www.toyotani.org/lib/lib/toyotani2017s.jpg -q -O target.jpg # 写真をダウンロードする
input_image = cv2.imread("./target.jpg") # 写真データを変数に代入する
#input_image = cv2.imread("./ここを自分の写真のファイル名にする.jpg")# オリジナル写真を指定する時は上の行をコメントにして、こちらの最初の#を無くしてコメントでは無く、有効にする
height, width, chanel = input_image.shape # 写真の幅や高さを取得する
input_image = cv2.resize(input_image,(int (width/3), int (height/3) )) # 写真が大きいために幅や高さを1/3に変換する
cv2_imshow(input_image) # 写真を画面に表示する(下記左側)
# この画像を使って推論を実行するために detectron2 config の設定部分と detectron2 DefaultPredictor の推測部分を記述する
configure = get_cfg()
# モデル固有の各種設定値 を読み込む
configure.merge_from_file(model_zoo.get_config_file("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml")) # Detectron2のModel ZooからFaster R-CNNの設定値を取得する。
configure.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # 物体検出は0.0から1.0までの確率が得られるため、検出したい閾値threshold を設定をする(この値以上が表示される)
# detectron2 の model zooを利用して、Faster R-CNNの学習済みモデルデータを読み込む
configure.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml") # Detectron2のModel ZooからFaster R-CNNの学習済みモデルデータを取得する。
predictor = DefaultPredictor(configure)# 画像から物体検出を行って物体が何であるかを推測するpredictorを生成する。
outputs = predictor(input_image)# predictorを使って、画像input_imageから物体検出を行う
# 画像に推測された物体を枠で囲んで表示する
objects = Visualizer(input_image[:, :, ::-1], MetadataCatalog.get(configure.DATASETS.TRAIN[0]), scale=1.0) #input_image[高さ方向全部, 幅方向全部, BGRをRGBにするために-1で反対方向から読み込む] MetadataCatalog.get(configure.DATASETS.TRAIN[0])はメタデータの読み込み(クラス分類後のpersonやcarなどの見出しを表示するため)。scaleは表示する結果画像の大きさ1.0は100%
box_objects = objects.draw_instance_predictions(outputs["instances"].to("cpu")) # 検出した部分に枠と塗りつぶしをする
cv2_imshow(box_objects.get_image()[:, :, ::-1]) # 検出結果画像を画面に表示する(下記右側)
 
---------------------------------------
#Panoptic Segmentation: Facebookの人工知能研究グループにより初期開発されたPyTorchのdetectron2を利用した物体認識処理プログラム。GoogleColaboratory は標準でPyTorchが組み込まれているので、!pip install torchvision等は不要
#GoogleColaboratoty の[ランタイム]→[ランタイムのタイムを変更]→[ハードウェアアクセラレータを"GPU"にする]
!python -m pip install pyyaml==5.1 # YAMLデータファイルを使用するのでPyYAMLというライブラリが必要
import sys, os, distutils.core #後でDistutilsを使うためにdistutils.coreを読み込む必要がある
!git clone 'https://github.com/facebookresearch/detectron2' #detectron2というInstance Segmentationの機能を、ネットから自分の作業場所にclone(コピー)する
dist = distutils.core.run_setup("./detectron2/setup.py") # detectron2を利用するために必要なセットアップを行う
!python -m pip install {' '.join([f"'{x}'" for x in dist.install_requires])}
sys.path.insert(0, os.path.abspath('./detectron2')) #detectron2の中に置いたパッケージ・ライブラリがいつでも使えるようになる
import torch, detectron2 #Detectron2は Facebook AIが開発した、インスタンスセグメンテーション用PyTorchベースの物体検出のライブラリ
!nvcc --version
TORCH_VERSION = ".".join(torch.__version__.split(".")[:2])
CUDA_VERSION = torch.__version__.split("+")[-1] # cuda versionのチェック
print("torch: ", TORCH_VERSION, "; cuda: ", CUDA_VERSION)
print("detectron2:", detectron2.__version__)
# Detectron2 loggerの設定
import detectron2
from detectron2.utils.logger import setup_logger
setup_logger()
# 共通ライブラリの読み込み
import numpy as np #行列計算ライブラリ
import os, json, cv2, random # osファイルやディレクトリの操作などの読み込み
from google.colab.patches import cv2_imshow # GoogleColaboratoryでcv_imshowを実行するのに利用
# detectron2 utilitiesの共通部品を読み込む
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
from detectron2.utils.visualizer import Visualizer
from detectron2.data import MetadataCatalog, DatasetCatalog
!wget https://www.toyotani.org/lib/lib/toyotani2017s.jpg -q -O target.jpg # 写真をダウンロードする
input_image = cv2.imread("./target.jpg") # 写真データを変数に代入する
#input_image = cv2.imread("./ここを自分の写真のファイル名にする.jpg")# オリジナル写真を指定する時は上の行をコメントにして、こちらの最初の#を無くしてコメントでは無く、有効にする
height, width, chanel = input_image.shape # 写真の幅や高さを取得する
height, width, chanel = input_image.shape # 写真の幅や高さを取得する
input_image = cv2.resize(input_image,(int (width/3), int (height/3) )) # 写真が大きいために幅や高さを1/3に変換する
cv2_imshow(input_image) # 写真を画面に表示する(下記左側)
# この画像を使って推論を実行するために detectron2 config の設定部分と detectron2 DefaultPredictor の推測部分を記述する
configure = get_cfg()
# モデル固有の各種設定値 を読み込む
configure.merge_from_file(model_zoo.get_config_file("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml")) # Detectron2のModel ZooからMask R-CNN のPanoptic FPN の設定値を読み込む。
configure.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.8 # 物体検出は0.0から1.0までの確率が得られるため、検出したい閾値threshold を設定をする(この値以上が表示される)
# detectron2 の model zooを利用して、Mask R-CNN のPanoptic FPNの学習済みモデルデータを読み込む
configure.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-PanopticSegmentation/panoptic_fpn_R_101_3x.yaml") # Detectron2のModel ZooからMask R-CNN のPanoptic FPNの学習済みモデルデータを取得する。
predictor = DefaultPredictor(configure)# 画像から物体検出を行って物体が何であるかを推測するpredictorを生成する。
panoptic_seg, segments_info = predictor(input_image)["panoptic_seg"]# predictorを使って、画像input_imageから物体検出を行う(領域の分類とその情報を得る)
# 画像に推測された物体を枠で囲んで表示する
objects = Visualizer(input_image[:, :, ::-1], MetadataCatalog.get(configure.DATASETS.TRAIN[0]), scale=1.0) #input_image[高さ方向全部, 幅方向全部, BGRをRGBにするために-1で反対方向から読み込む] MetadataCatalog.get(configure.DATASETS.TRAIN[0])はメタデータの読み込み(クラス分類後のpersonやcarなどの見出しを表示するため)。scaleは表示する結果画像の大きさ1.0は100%
box_objects = objects.draw_panoptic_seg_predictions(panoptic_seg.to("cpu"), segments_info) # 検出した部分を塗りつぶす # 検出した領域を塗りつぶす
cv2_imshow(box_objects.get_image()[:, :, ::-1]) # 検出結果画像を画面に表示する(下記右側)

#物体検出AIの代表的なYOLOv8を利用した物体検出
!pip install ultralytics #YOLOの中でもultralyticsを利用したものがver.8になる
from ultralytics import YOLO #Yoloのultralyticsを読み込む
model = YOLO("yolov8x.pt") #いくつかの学習済みモデルがあるが、その中で精度の高いyolov8x.ptを利用する
results = model("https://www.toyotani.org/lib/lib/toyotani2017s.jpg",save=True) #画像を指定して物体認識をする(検出結果は[runs]->[detect]->[predict?]の中に保存される.)。

#YOLOv8を利用した信号検出
!pip install ultralytics #YOLOの中でもultralyticsを利用したものがver.8になる
from ultralytics import YOLO #Yoloのultralyticsを読み込む
model = YOLO("yolov8x.pt") #いくつかの学習済みモデルがあるが、その中で精度の高いyolov8x.ptを利用する
results = model("https://www.toyotani.org/lib/lib/red.jpg",save=True, classes=[9], conf=0.3) # classes=[9]で信号9のみを検出させる, conf=0.3は信頼度30%以上の物体に限定する。画像を指定して物体認識をする(検出結果は[runs]->[detect]->[predict?]の中に保存される.)。
#まだこれでは自動車用も歩行者用も青信号も赤信号もまとめて[traffic light]と認識される。
#物体認識後に、縦長であれば歩行者用などと判別し、さらに上側が赤色か下側が緑色か色の判別処理をして、赤信号と青信号の判別が可能になる。
 
#OpenCVのカスケード分類器を利用したAI信号認識プログラム:機械学習で赤い信号を認識
#機械学習に使った赤信号の教師データ画像の例(機械学習時には、これらを基に1000枚以上の画像を自動生成して実行した)

   
   
#AI認識に利用した画像
 
import cv2
from google.colab.patches import cv2_imshow# GoogleColaboratoryでcv_imshowを実行するのに利用
import urllib.request as req # URL指定でファイルをダウンロードするのに利用
url_img = 'https://www.toyotani.org/lib/lib/red_signal.jpg' # 歩行者信号で赤信号の写真 Web上のデータの場所を指定(既にファイルがあればこの処理不要)
#url_img = 'https://www.toyotani.org/lib/lib/blue_signal.jpg' # 歩行者信号で青信号の写真 Web上のデータの場所を指定(既にファイルがあればこの処理不要)
req.urlretrieve(url_img, "target.jpg") # 入力画像としてGoogleColaboratoryに保存(既にファイルがあればこの処理不要)
img = cv2.imread("target.jpg") # 入力画像の読み込み
# カスケード型識別器(自作:歩行者赤信号の学習結果)学習時に画像特徴量を抽出しそこから分類器を作成する手法
xml_red = 'https://www.toyotani.org/lib/lib/RED_cascade.xml' # Web上のデータの場所を指定(既にファイルがあればこの処理不要)
xml_blue = 'https://www.toyotani.org/lib/lib/BLUE_cascade.xml' # Web上のデータの場所を指定(既にファイルがあればこの処理不要)
req.urlretrieve(xml_red , "RED_cascade.xml") # 学習後のデータファイルとしてGoogleColaboratoryに保存(既にファイルがあればこの処理不要)
req.urlretrieve(xml_blue, "BLUE_cascade.xml") # 学習後のデータファイルとしてGoogleColaboratoryに保存(既にファイルがあればこの処理不要)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 入力画像をグレースケールにしてデータ量を小さくして処理をする
#赤信号の認識
cascade = cv2.CascadeClassifier("RED_cascade.xml") # RED_cascade.xmlは機械学習後のデータファイル
signal = cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=2, minSize=(20, 20))# gray:グレースケール画像を読み込む, scaleFactor:デフォルトは1.1で1.0より大きい値で指定する。画像スケールを何度も変化させて探索する時の縮小率, minNeighbors:デフォルトは3で最低でもこの数だけの近傍矩形を含む, minSize:検出の最小サイズ
# 領域を四角形で囲む
for (x, y, w, h) in signal:
print("x,y,w,h=",x,y,w,h)#x,y座標と幅と高さ
# 四角描画を始点のx,yから、終点のx+w, y+hまで枠を書く
cv2.rectangle(img, (x, y), (x + w, y+h), (128,128,255), 5) #薄い赤色で信号を囲む
#青信号の認識
cascade = cv2.CascadeClassifier("BLUE_cascade.xml") # RED_cascade.xmlは機械学習後のデータファイル
signal = cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=2, minSize=(20, 20))
# 領域を四角形で囲む
for (x, y, w, h) in signal:
print("x,y,w,h=",x,y,w,h)#x,y座標と幅と高さ
# 四角描画を始点のx,yから、終点のx+w, y+hまで枠を書く
cv2.rectangle(img, (x, y), (x + w, y+h), (128,255,128), 5) #薄い青色で信号を囲む
# 結果画像を保存
cv2.imwrite("result.jpg",img)
#結果画像を画面表示
cv2_imshow(img)
#認識結果
 
#151 198 68 68 326 461 98 98
#この後、改良を進めたが、実際に信号を認識させる場合は、今回のような点灯している内側のレンズ部分だけでなく、下のように無点灯の部分や、外側の枠までを含めて次のように学習させた方が認識率は上がる事が分かった。
 
#下記の左は実際に組み込み型PC・小型PCに実装した例で、中央の黒色がPC本体、左下がバッテリー、右下がWebカメラ、奥の白は視覚障碍者向けの振動子である。赤信号や青信号で特定のサインを手に伝えることによって、視覚障がい者は信号を判別する事ができる。右側写真はこれを視覚障碍者が操作できるようにキャリー型にした試作機である。ただしカスケード分類では、入力画像が斜めになったり歪んだりすると認識精度が悪くなるため認識精度を向上させるためCNN等を適用すると処理が重たく自動判定が遅くなる。そこでさらに高速なアルゴリズムを適用するなど試行錯誤を行っている。このように組み込み型の製品を考えると、本体の処理能力やアルゴリズムなどのバランスを総合的に判断して全体を設計する必要がある。
 
|