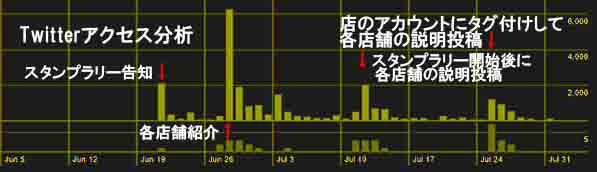
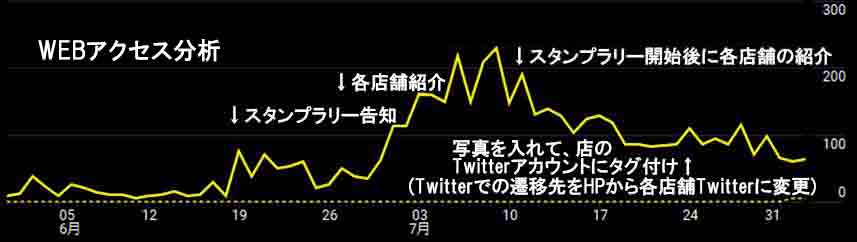
ゼミで学ぶ内容
初心者歓迎でIT技術やデータサイエンス・人工知能のプログラミング技術も学びながら、実学として企業の方々とコラボで実際の経営問題を扱います。具体的には企業と共同でマーケティングや商品企画戦略を検討してSNS動画を提供したり、地域の企業や商店街と協力して地域活性化のための活動をしています。特に企業と共同研究を行うことによって、机上の演習では無く、実際のデータを分析することが出来て、かつ経営者の考えを習得して、自分の企画提案に対するコメントを受けて、将来へ向けて経験を積む事が出来ます。